# load packages
library(tidyverse) # for data wrangling
library(tidymodels) # for modeling
library(fivethirtyeight) # for the fandango dataset
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_minimal(base_size = 16))
# set default figure parameters for knitr
knitr::opts_chunk$set(
fig.width = 8,
fig.asp = 0.618,
fig.retina = 3,
dpi = 300,
out.width = "80%"
)Simple Linear Regression
STA 210 - Summer 2022
Movie ratings
- Data behind the FiveThirtyEight story Be Suspicious Of Online Movie Ratings, Especially Fandango’s
- In the fivethirtyeight package:
fandango - Contains every film that has at least 30 fan reviews on Fandango, an IMDb score, Rotten Tomatoes critic and user ratings, and Metacritic critic and user scores




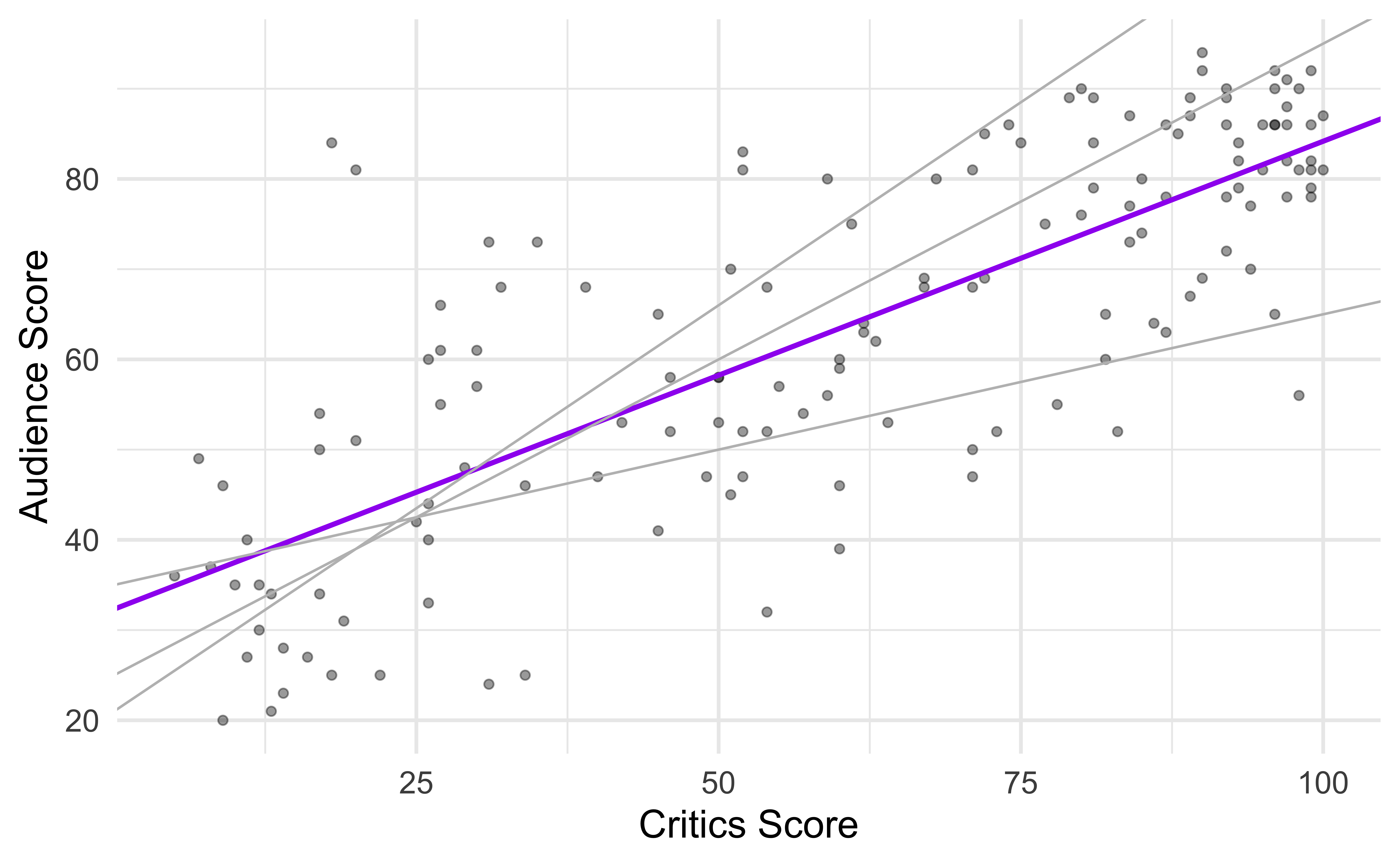
Data visualization
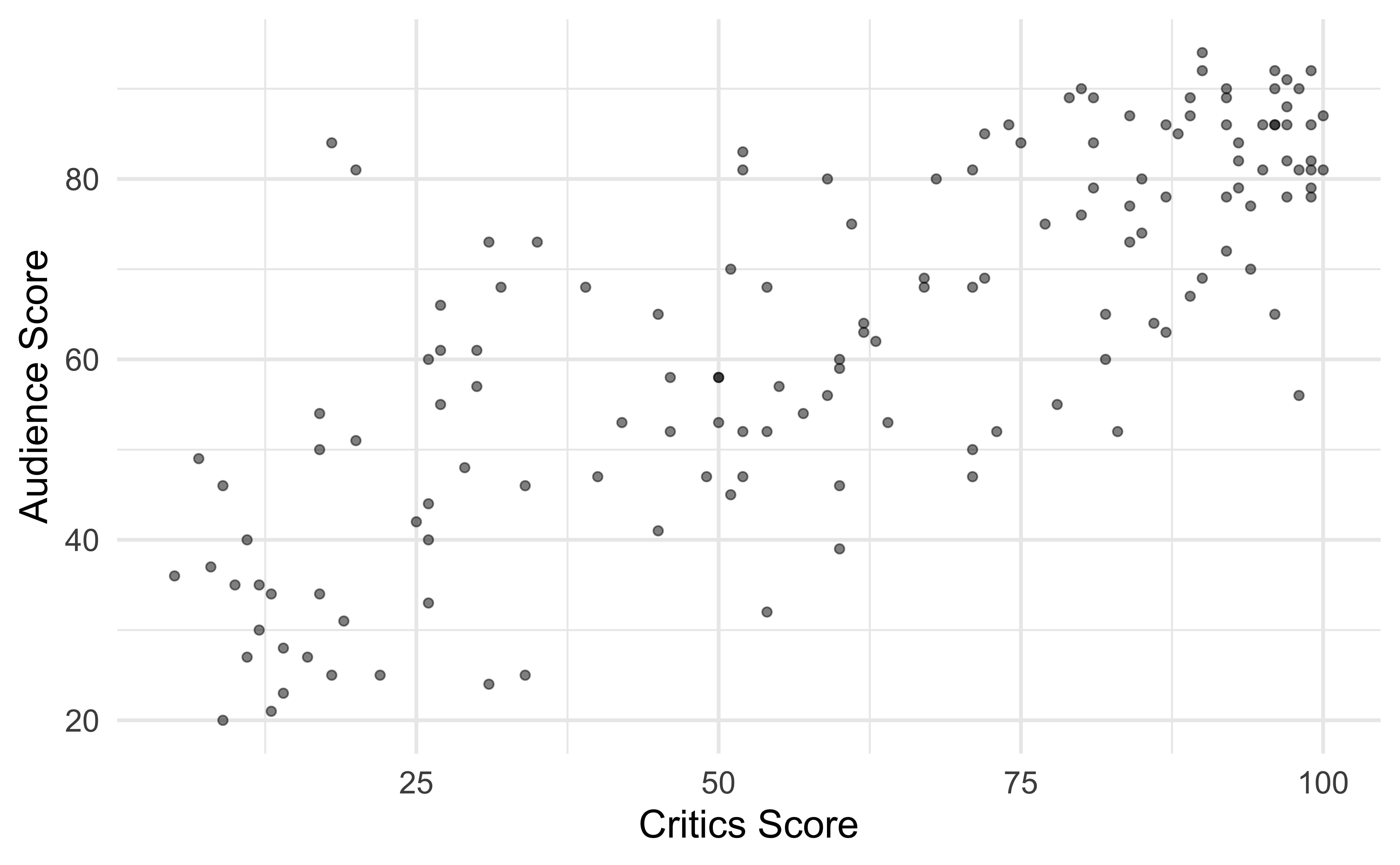
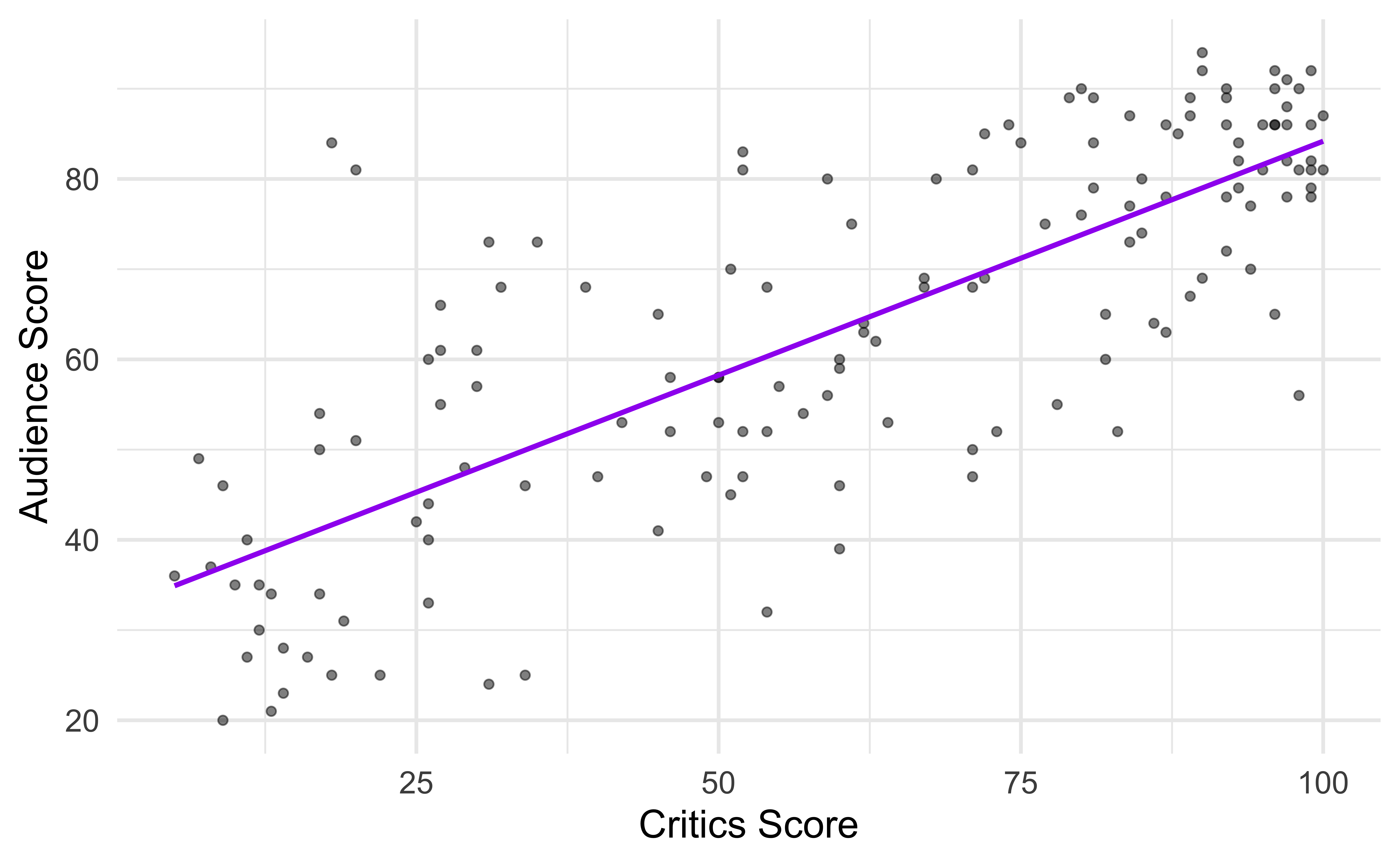
Fit a line
… to describe the relationship between the critics and audience score
Terminology
- Outcome, Y: variable describing the outcome of interest
- Predictor, X: variable used to help understand the variability in the outcome
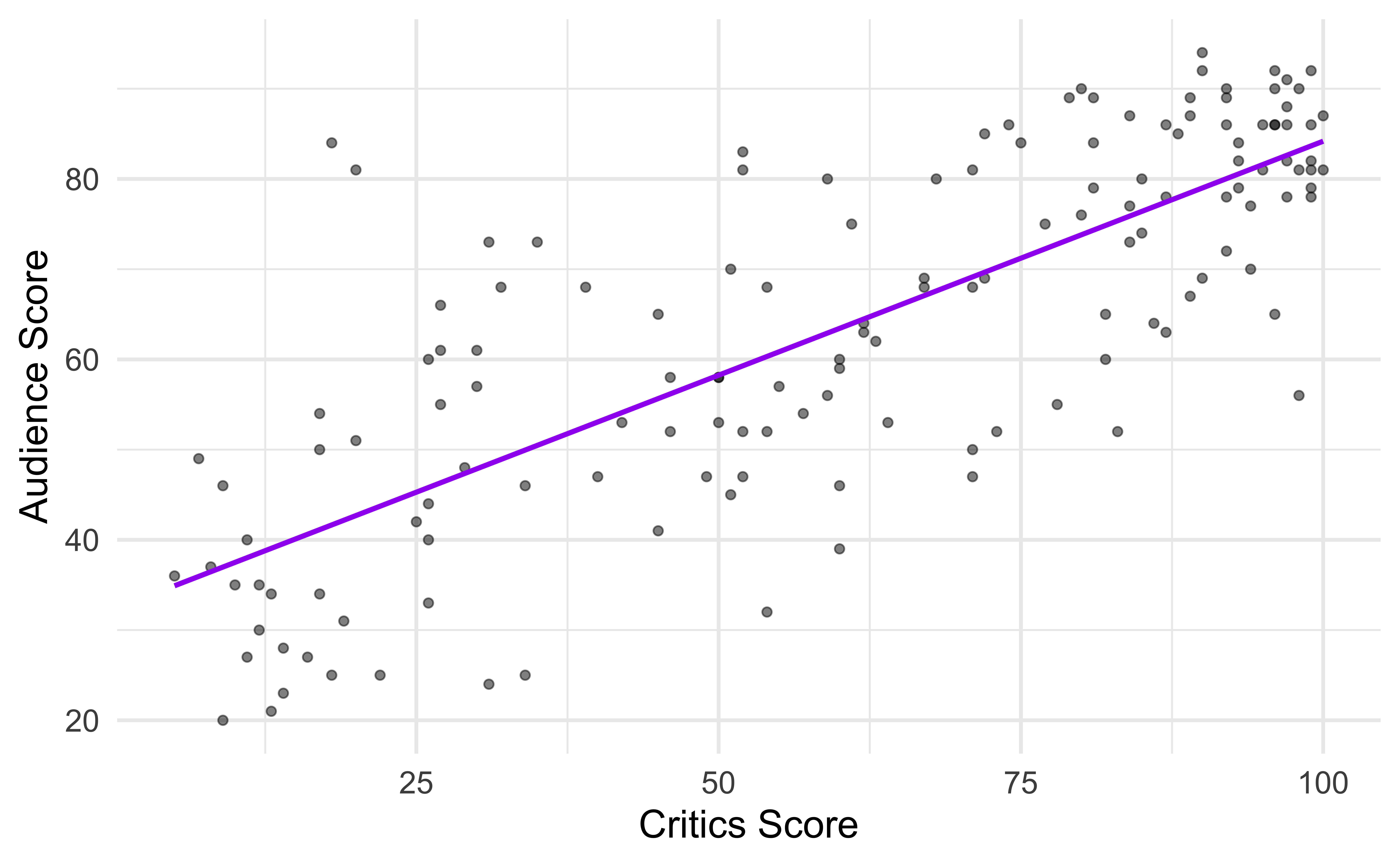
Regression model
$$
\[\begin{aligned} Y &= \color{purple}{\textbf{Model}} + \text{Error} \\[8pt]
&= \color{purple}{\mathbf{f(X)}} + \epsilon \\[8pt]
&= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \epsilon
\end{aligned}\]
$$
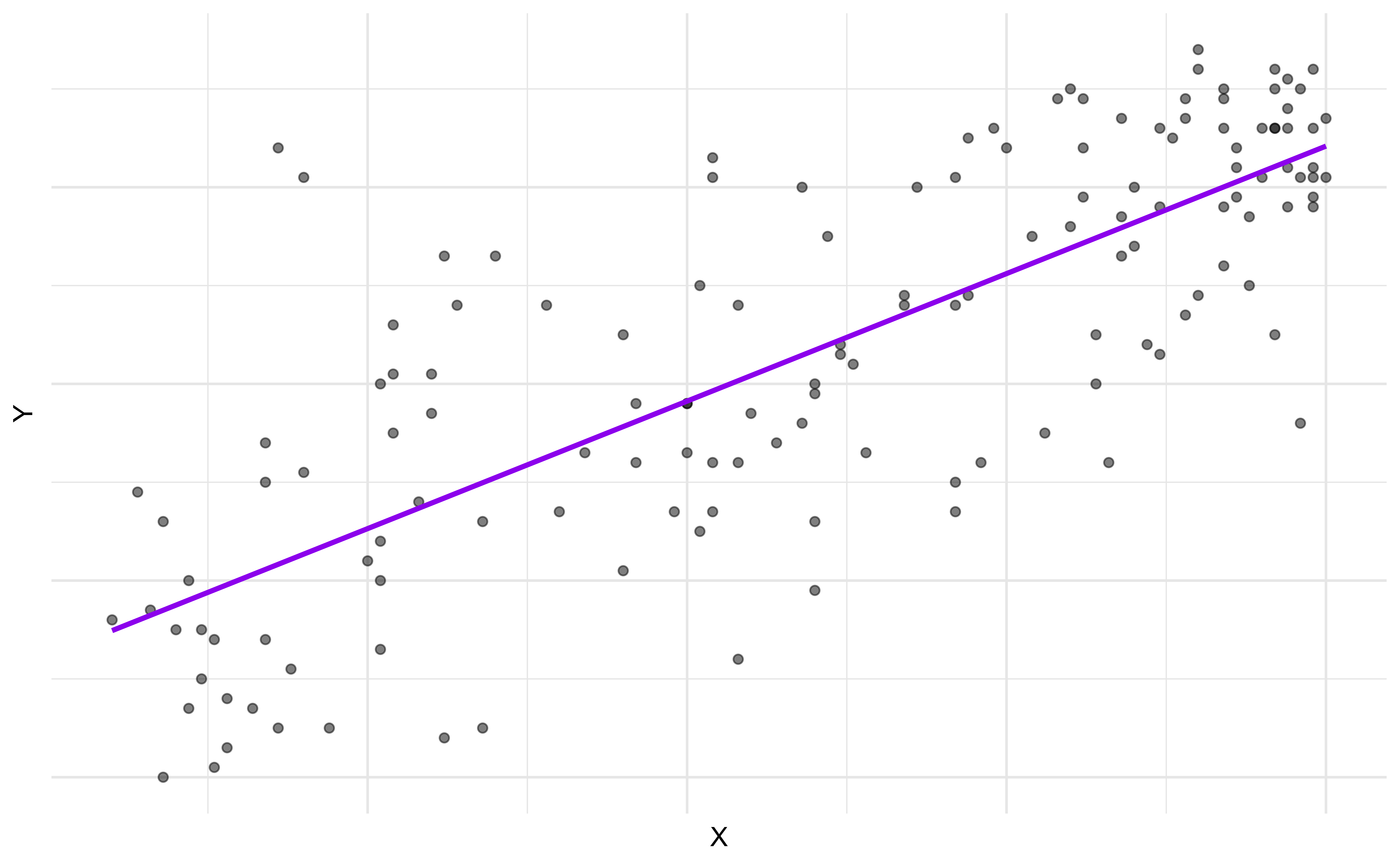
Regression model + residuals
\[\begin{aligned} Y &= \color{purple}{\textbf{Model}} + \color{blue}{\textbf{Error}} \\[8pt] &= \color{purple}{\mathbf{f(X)}} + \color{blue}{\boldsymbol{\epsilon}} \\[8pt] &= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \color{blue}{\boldsymbol{\epsilon}} \\[8pt] \end{aligned}\]
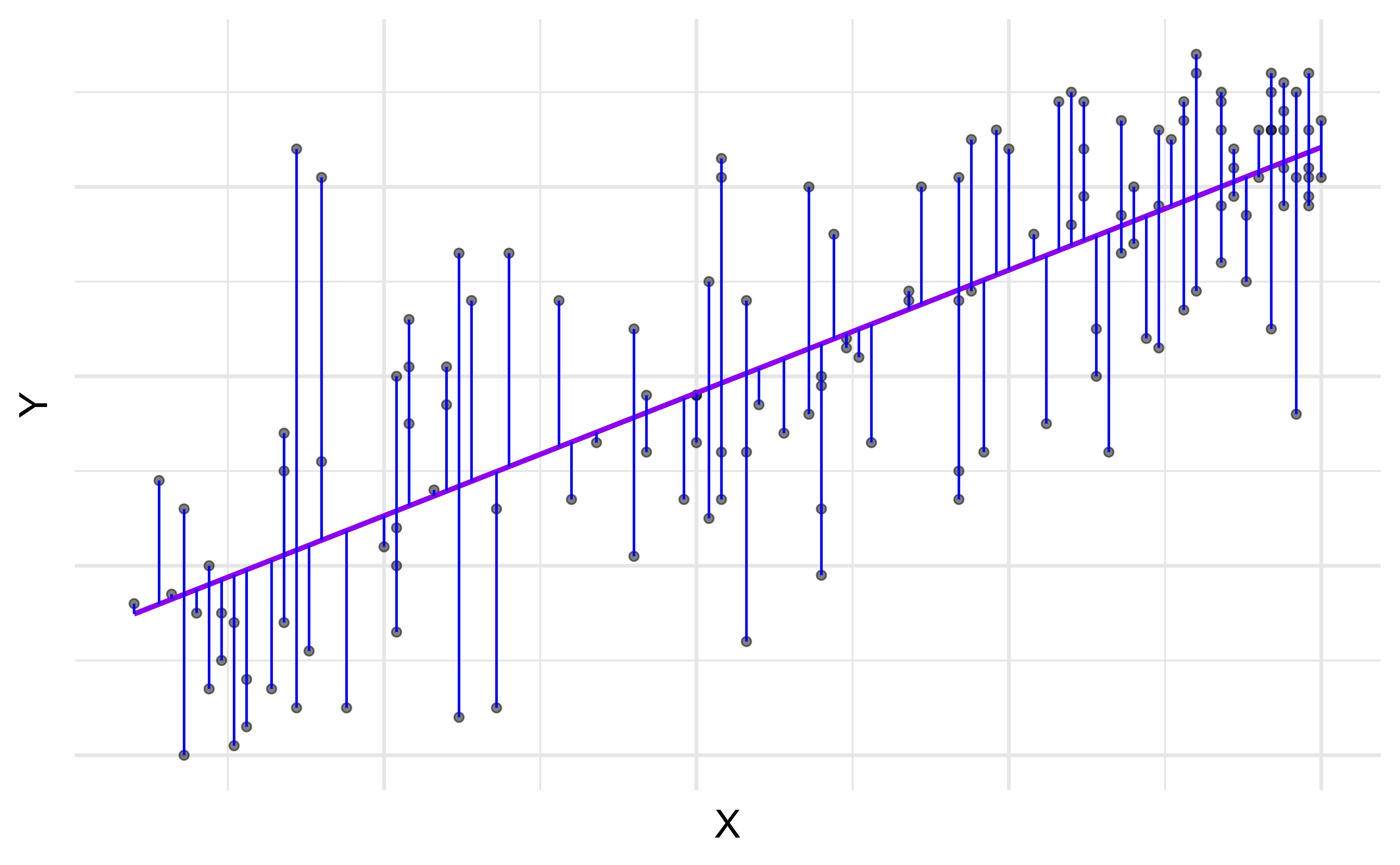
Choosing values for \(\hat{\beta}_1\) and \(\hat{\beta}_0\)
Residuals
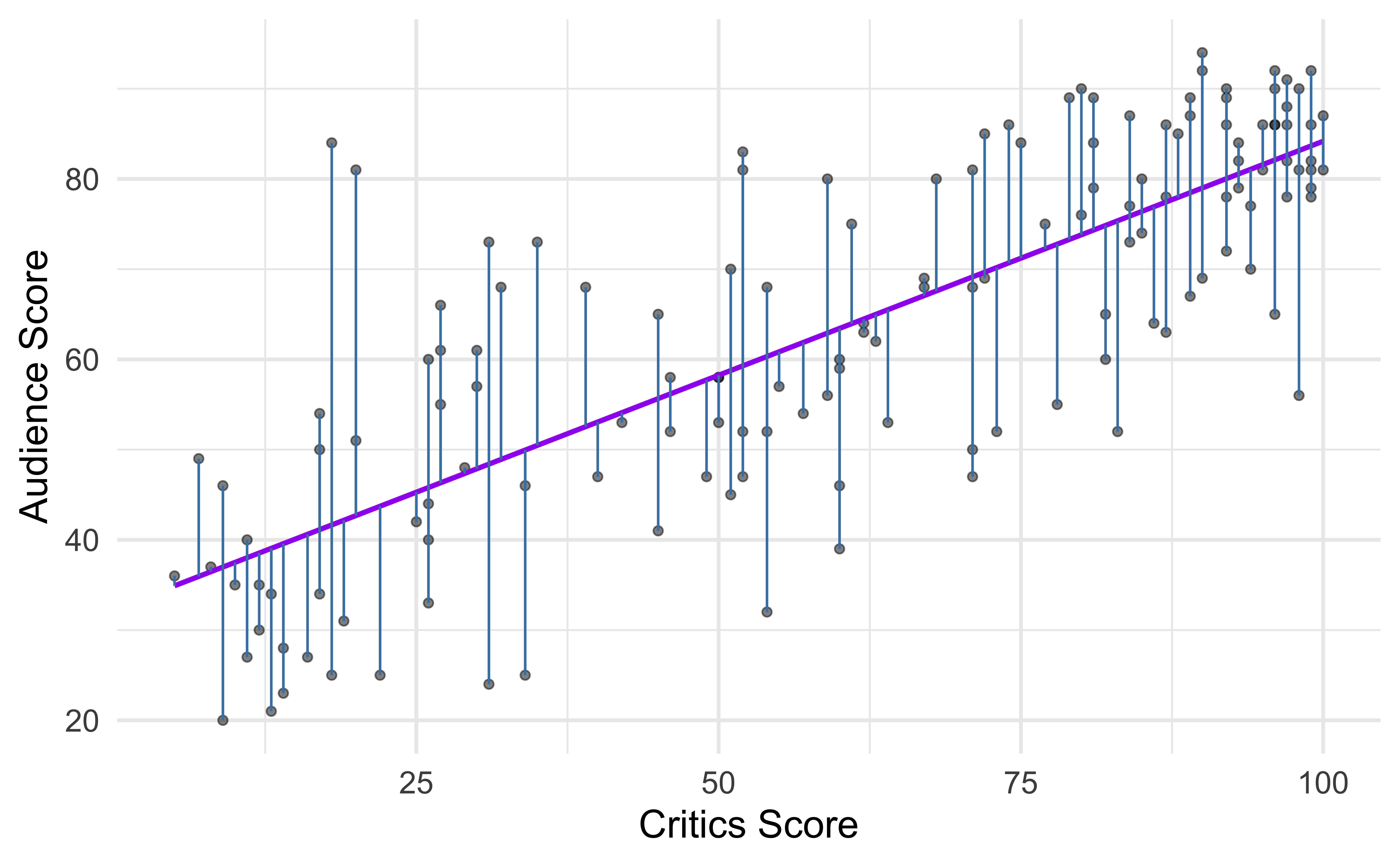
\[\text{residual} = \text{observed} - \text{predicted} = y - \hat{y}\]
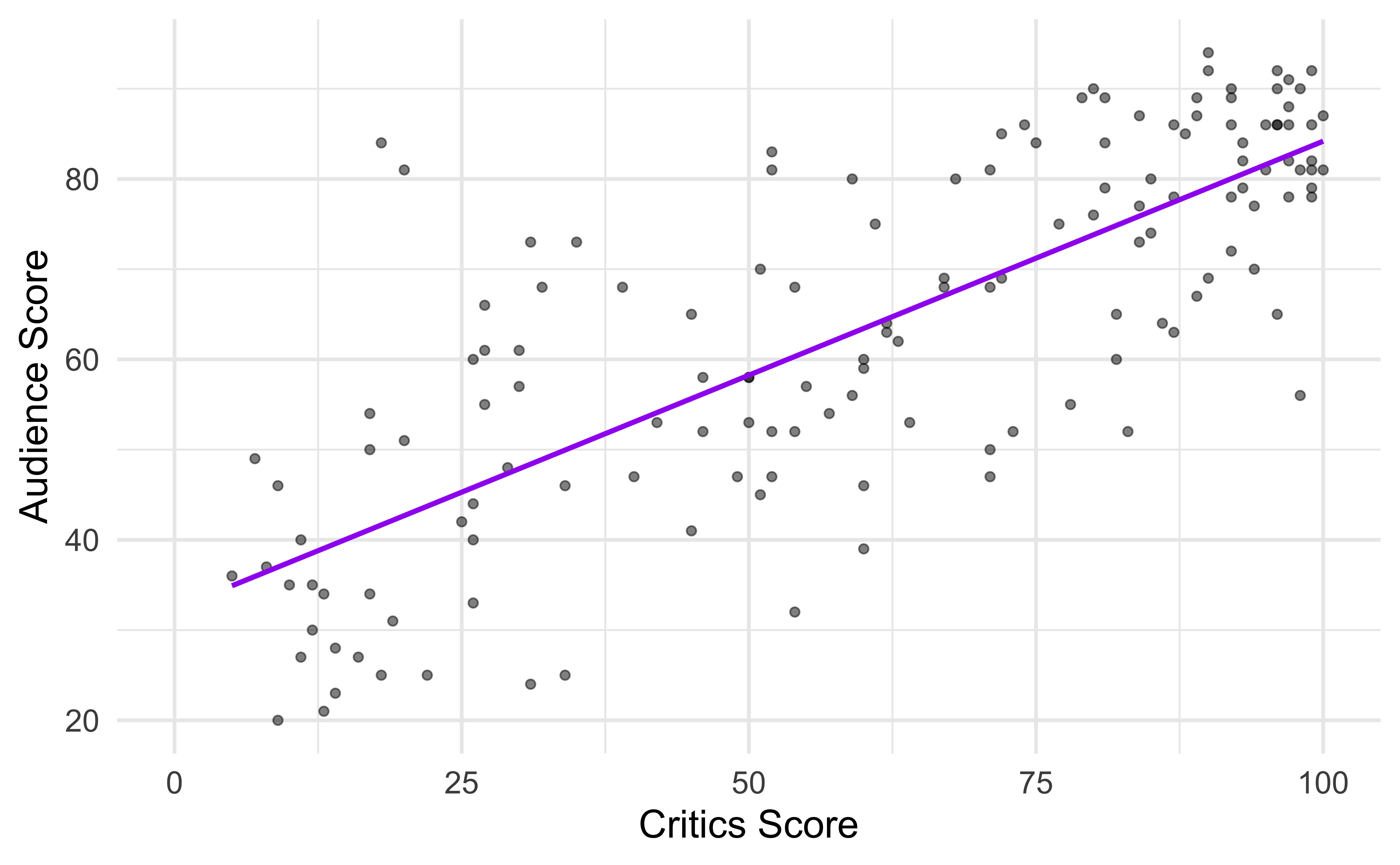
Extrapolation
Extrapolation is prediction outside of the ranged covered by data.
Suppose that a movie has a critics score of 0. According to this model, what is the movie’s predicted audience score?
Recap
Used simple linear regression to describe the relationship between a quantitative predictor and quantitative outcome variable.
Used the least squares method to estimate the slope and intercept.
We interpreted the slope and intercept.
- Slope: For every one unit increase in \(x\), we expect y to be higher/lower by \(\hat{\beta}_1\) units, on average.
- Intercept: If \(x\) is 0, then we expect \(y\) to be \(\hat{\beta}_0\) units.
Predicted the response given a value of the predictor variable.
Defined extrapolation and why we should avoid it.